When you give a SQL Query a candidate class, it will
return persistent instances of that class. At a minimum, your SQL must select
the class' primary key columns, discriminator column (if mapped), and version
column (also if mapped). The JPA runtime uses the values of the primary key
columns to construct each result object's identity, and possibly to match it
with a persistent object already in the EntityManager's
cache. When an object is not already cached, the implementation creates a new
object to represent the current result row. It might use the discriminator
column value to make sure it constructs an object of the correct subclass.
Finally, the query records available version column data for use in optimistic
concurrency checking, should you later change the result object and flush it
back to the database.
Aside from the primary key, discriminator, and version columns, any columns you select are used to populate the persistent fields of each result object. JPA implementations will compete on how effectively they map your selected data to your persistent instance fields.
Let's make the discussion above concrete with an example. It uses the following simple mapping between a class and the database:
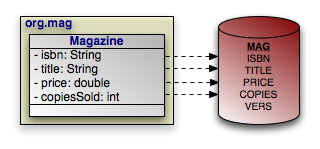 |
Example 11.2. Retrieving Persistent Objects
Query query = em.createNativeQuery("SELECT ISBN, TITLE, PRICE, "
+ "VERS FROM MAG WHERE PRICE > 5 AND PRICE < 10", Magazine.class);
List<Magazine> results = (List<Magazine>) query.getResultList();
for (Magazine mag : results)
processMagazine(mag);
The query above works as advertised, but isn't very flexible. Let's update it to take in parameters for the minimum and maximum price, so we can reuse it to find magazines in any price range:
Example 11.3. SQL Query Parameters
Query query = em.createNativeQuery("SELECT ISBN, TITLE, PRICE, "
+ "VERS FROM MAG WHERE PRICE > ?1 AND PRICE < ?2", Magazine.class);
query.setParameter(1, 5d);
query.setParameter(2, 10d);
List<Magazine> results = (List<Magazine>) query.getResultList();
for (Magazine mag : results)
processMagazine (mag);
Like JDBC prepared statements, SQL queries represent parameters with question marks, but are followed by an integer to represent its index.